|
|
numpy 比原生的 python 计算更省资源、速度更快
|
|
|
|
Wall time: 20 ms
|
|
Wall time: 969 ms
创建数组 ndarray
array、arange 方法创建数组
|
|
[1 2 3] <class 'numpy.ndarray'>
[0 1 2 3 4 5 6 7 8 9]
[0 1 2 3 4 5 6 7 8 9]
|
|
dtype('int64')
数据类型
|
|
dtype('float64')
|
|
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=int8)
|
|
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=int8)
数据类型列表
| 类型 | 类型代码 | 说明 |
|---|---|---|
int8\uint8 |
i1\u1 |
有符号\无符号的 8 位(1 字节)整数 |
int16\uint16 |
i1\u1 |
有符号\无符号的 16 位(2 字节)整数 |
int32\uint32 |
i1\u1 |
有符号\无符号的 32 位(4 字节)整数 |
int64\uint64 |
i1\u1 |
有符号\无符号的 64 位(8 字节)整数 |
float16 |
f2 |
半精度浮点数 |
float32 |
f4或f |
标准单精度浮点数。与 C 的 float 兼容 |
float64 |
f8或d |
标准双精度浮点数。与 C 的 double 和 python 的 float 兼容 |
float128 |
f16或g |
扩展精度浮点数 |
complex64\complex128\complex256 |
c8\c16\c32 |
分别用两个 32 位、64 位、128 为的浮点数表示复数 |
bool |
? |
存储 True 和 False 值的布尔类型 |
object |
O |
Python 对象类型 |
string_ |
S |
固定长度的字符串类型(每个字符 1 个字节)。例如,要创建一个长度为 10 的字符串,使用 S10 |
unicode_ |
U |
固定长度的 unicode 类型(字节数由平台决定)。跟字符串一样,如 U10 |
创建多维数组
|
|
array([[1, 2, 3],
[4, 5, 6]])
获取数组的形状 shape
|
|
(2, 3)
改变数组的形状 reshape、flatten、ravel
|
|
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
|
|
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23])
|
|
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23])
创建全是 0 的数组
|
|
array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]])
|
|
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
创建全是 1 的数组
|
|
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]])
|
|
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
创建一个对角线为 1 的正方形数组(方阵)
|
|
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
创建空数组 empty
empty 只是分配了空间并未填充任何的值,下面看到的值可以理解成历史数据
|
|
array([2.15968811e-316, 0.00000000e+000, 2.37986283e-316, 2.39281447e-316,
1.35807731e-312])
|
|
array([[1.12409068, 0.71737825, 1.91333048],
[0.95169061, 1.36121775, 1.16378946]])
创建填充指定值的数组
|
|
array([2, 2, 2, 2, 2])
|
|
array([[3, 3, 3],
[3, 3, 3]])
生成随机的数组
|
|
array([[-1.12409068, -0.71737825, -1.91333048],
[-0.95169061, -1.36121775, 1.16378946]])
|
|
array([-0.09859757, -1.94489982, -0.2328898 , 1.21339405, -2.6686755 ,
1.01910496, 0.39283428, -0.74445077, 0.16423021, -0.71799976])
|
|
array([[ 1.38710548, -0.99141781, -0.01657807, 0.28104076],
[-0.72489278, 0.14099596, -0.61639653, 1.31648008],
[ 0.12896794, -0.31226401, 1.64074497, 0.18071008],
[ 0.30653902, 1.42660833, -0.63305582, 3.74709392]])
随机方法列表
| 函数 | 说明 |
|---|---|
| seed | 确定随机数生成器的种子,让每次随机数据一样 |
| permutation | 返回一个序列的随机排列或返回一个随机排列的范围 |
| shuffle | 对一个序列就地随机排列 |
| rand | 产生均匀分布的样本值 |
| randint | 从给定的上下限范围内随机选取整数 |
| randn | 产生正态分布(平均值为 0,标准差为 1)的样本值,类似于 MATLAB 接口 |
| binomial | 产生二项分布的样本值 |
| normal | 产生正态(高斯)分布的样本值 |
| beta | 产生 Beta 分布的样本值 |
| chisquare | 产生卡方分布的样本值 |
| gamma | 产生 Gamma 分布的样本值 |
| uniform | 产生在 [0, 1) 中均匀分布的样本值 |
转置(交换轴)
转置就是交换轴
|
|
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
|
|
array([[ 0, 6, 12, 18],
[ 1, 7, 13, 19],
[ 2, 8, 14, 20],
[ 3, 9, 15, 21],
[ 4, 10, 16, 22],
[ 5, 11, 17, 23]])
|
|
array([[ 0, 6, 12, 18],
[ 1, 7, 13, 19],
[ 2, 8, 14, 20],
[ 3, 9, 15, 21],
[ 4, 10, 16, 22],
[ 5, 11, 17, 23]])
|
|
[[[ 0 1 2 3]
[ 4 5 6 7]]
[[ 8 9 10 11]
[12 13 14 15]]] (2, 2, 4)
array([[[ 0, 1, 2, 3],
[ 8, 9, 10, 11]],
[[ 4, 5, 6, 7],
[12, 13, 14, 15]]])
|
|
array([[ 0, 6, 12, 18],
[ 1, 7, 13, 19],
[ 2, 8, 14, 20],
[ 3, 9, 15, 21],
[ 4, 10, 16, 22],
[ 5, 11, 17, 23]])
索引与切片
|
|
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
选取行
|
|
array([ 6, 7, 8, 9, 10, 11])
|
|
array([[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
|
|
array([[ 6, 7, 8, 9, 10, 11],
[18, 19, 20, 21, 22, 23]])
选取列
|
|
array([ 1, 7, 13, 19])
|
|
array([[ 1, 2, 3],
[ 7, 8, 9],
[13, 14, 15],
[19, 20, 21]])
|
|
array([[ 1, 3],
[ 7, 9],
[13, 15],
[19, 21]])
选取点
|
|
7
|
|
array([ 7, 21])
修改数值
可以对索引获取到的值进行修改
|
|
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
|
|
array([[ 0, 0, 2, 3, 4, 5],
[ 6, 0, 8, 9, 10, 11],
[12, 0, 14, 15, 16, 17],
[18, 0, 20, 21, 22, 23]])
布尔索引
|
|
array([[ 3, 3, 3, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
|
|
array([[False, False, False, False, False, False],
[False, False, False, False, False, False],
[False, False, False, False, False, False],
[False, False, False, False, False, False]])
|
|
array([[ 3, 3, 3, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
三元运算 where
|
|
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
|
|
array([[ 0, 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0, 20],
[20, 20, 20, 20, 20, 20],
[20, 20, 20, 20, 20, 20]])
裁剪 clip
把小于某值的改成某值、把大于某值的改成某值
|
|
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
|
|
array([[10, 10, 10, 10, 10, 10],
[10, 10, 10, 10, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 18, 18, 18, 18, 18]])
|
|
array([[ 0., 1., 2., 3., 4., 5.],
[ 6., 7., 8., 9., 10., 11.],
[12., 13., 14., 15., 16., 17.],
[18., 19., 20., nan, nan, nan]])
|
|
array([[10., 10., 10., 10., 10., 10.],
[10., 10., 10., 10., 10., 11.],
[12., 13., 14., 15., 16., 17.],
[18., 18., 18., nan, nan, nan]])
非数值 nan 和无穷 inf
nan 表示非数值类型,inf 表示正无穷,-inf 表示负无穷;这俩都是 float 类型的
|
|
float
|
|
float
nan和任何数值计算都是nan,nan不等于nan,判断是否是nan可以用 isnan()
|
|
True
|
|
array([ 1., 3., nan])
|
|
array([False, False, True])
|
|
1
|
|
array([False, False, True])
|
|
array([1., 3., 0.])
数学运算
numpy 的计算有个广播效应,会逐个元素、逐行、逐列进行计算
|
|
array([[1., 2.],
[3., 4.]])
|
|
array([[5., 6.],
[7., 8.]])
|
|
array([2, 3])
逐元素求和
|
|
array([[11., 12.],
[13., 14.]])
|
|
array([[ 6., 8.],
[10., 12.]])
|
|
array([[ 6., 8.],
[10., 12.]])
|
|
array([[3., 5.],
[5., 7.]])
逐元素作差
|
|
array([[-9., -8.],
[-7., -6.]])
|
|
array([[-4., -4.],
[-4., -4.]])
|
|
array([[-4., -4.],
[-4., -4.]])
|
|
array([[-1., -1.],
[ 1., 1.]])
逐元素相乘
|
|
array([[10., 20.],
[30., 40.]])
|
|
array([[ 5., 12.],
[21., 32.]])
|
|
array([[ 5., 12.],
[21., 32.]])
|
|
array([[ 2., 6.],
[ 6., 12.]])
逐元素相除
|
|
array([[0.1, 0.2],
[0.3, 0.4]])
|
|
array([[0.2 , 0.33333333],
[0.42857143, 0.5 ]])
逐元素求平方根
|
|
array([[1. , 1.41421356],
[1.73205081, 2. ]])
看图理解广播效应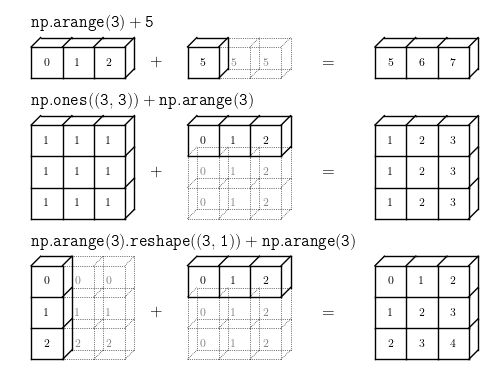
统计函数
|
|
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
求和
|
|
276
|
|
276
|
|
array([36, 40, 44, 48, 52, 56])
|
|
array([36, 40, 44, 48, 52, 56])
累加 cumsum
|
|
array([0, 0, 1, 0, 0, 1, 0, 0, 1, 0])
|
|
array([-1, -1, 1, -1, -1, 1, -1, -1, 1, -1])
|
|
array([-1, -2, -1, -2, -3, -2, -3, -4, -3, -4], dtype=int32)
求均值
|
|
11.5
|
|
11.5
|
|
array([ 9., 10., 11., 12., 13., 14.])
|
|
array([ 9., 10., 11., 12., 13., 14.])
求中值
|
|
11.5
|
|
array([ 9., 10., 11., 12., 13., 14.])
求最大值、最小值
|
|
23
|
|
23
|
|
array([18, 19, 20, 21, 22, 23])
|
|
array([18, 19, 20, 21, 22, 23])
|
|
0
|
|
0
|
|
array([0, 1, 2, 3, 4, 5])
|
|
array([0, 1, 2, 3, 4, 5])
求极值
最大值 减去 最小值
|
|
23
|
|
23
|
|
array([18, 18, 18, 18, 18, 18])
|
|
array([18, 18, 18, 18, 18, 18])
求标准差
|
|
6.922186552431729
|
|
6.922186552431729
|
|
array([6.70820393, 6.70820393, 6.70820393, 6.70820393, 6.70820393,
6.70820393])
|
|
array([6.70820393, 6.70820393, 6.70820393, 6.70820393, 6.70820393,
6.70820393])
缺失值填充均值
|
|
array([[ 0., 1., 2., 3., 4., 5.],
[ 6., 7., 8., 9., 10., 11.],
[12., 13., 14., 15., 16., 17.],
[18., 19., 20., 21., 22., 23.]])
|
|
array([[ 0., 1., 2., 3., 4., 5.],
[ 6., nan, 8., 9., 10., 11.],
[12., 13., 14., 15., 16., 17.],
[18., 19., 20., nan, 22., 23.]])
|
|
array([nan])
|
|
1
|
|
|
|
array([[ 0., 1., 2., 3., 4., 5.],
[ 6., 11., 8., 9., 10., 11.],
[12., 13., 14., 15., 16., 17.],
[18., 19., 20., 9., 22., 23.]])
数组的拼接 concatenate、vstack、hstack
|
|
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11]])
|
|
array([[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
竖直、横向拼接 concatenate
|
|
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
|
|
array([[ 0, 1, 2, 3, 4, 5, 12, 13, 14, 15, 16, 17],
[ 6, 7, 8, 9, 10, 11, 18, 19, 20, 21, 22, 23]])
竖直拼接 vstack
|
|
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
横向拼接 hstack
|
|
array([[ 0, 1, 2, 3, 4, 5, 12, 13, 14, 15, 16, 17],
[ 6, 7, 8, 9, 10, 11, 18, 19, 20, 21, 22, 23]])
数组的拆分 split
|
|
array([[0.51323562, 0.58188986, 0.96645492, 0.74560963, 0.25843771],
[0.66209902, 0.16546576, 0.35851699, 0.81376061, 0.18680752],
[0.42327984, 0.33418805, 0.61434484, 0.02092018, 0.7348934 ],
[0.6246003 , 0.4429335 , 0.99242307, 0.53883774, 0.93484283],
[0.45927832, 0.13045444, 0.90311103, 0.14345885, 0.62611419]])
|
|
[[0.51323562 0.58188986 0.96645492 0.74560963 0.25843771]]
[[0.66209902 0.16546576 0.35851699 0.81376061 0.18680752]
[0.42327984 0.33418805 0.61434484 0.02092018 0.7348934 ]]
[[0.6246003 0.4429335 0.99242307 0.53883774 0.93484283]
[0.45927832 0.13045444 0.90311103 0.14345885 0.62611419]]
|
|
[[0.51323562]
[0.66209902]
[0.42327984]
[0.6246003 ]
[0.45927832]]
[[0.58188986 0.96645492]
[0.16546576 0.35851699]
[0.33418805 0.61434484]
[0.4429335 0.99242307]
[0.13045444 0.90311103]]
[[0.74560963 0.25843771]
[0.81376061 0.18680752]
[0.02092018 0.7348934 ]
[0.53883774 0.93484283]
[0.14345885 0.62611419]]
行或列交换位置
利用 索引 进行 行与行、列与列的交换
|
|
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
行交换
|
|
array([[ 0, 1, 2, 3, 4, 5],
[12, 13, 14, 15, 16, 17],
[ 6, 7, 8, 9, 10, 11],
[18, 19, 20, 21, 22, 23]])
列交换
|
|
array([[ 0, 2, 1, 3, 4, 5],
[12, 14, 13, 15, 16, 17],
[ 6, 8, 7, 9, 10, 11],
[18, 20, 19, 21, 22, 23]])
线性代数
线性代数忘了,复习之后再补充
|
|
array([[1., 2., 3.],
[4., 5., 6.]])
|
|
array([[ 6., 23.],
[-1., 7.],
[ 8., 9.]])
|
|
array([[ 28., 64.],
[ 67., 181.]])
常用的线性代数方法
| 函数 | 说明 |
|---|---|
| diag | 以一维数组的形式返回方阵的对角线(或非对角线)元素,或将一组数组转换为方阵(非对角线元素为 0) |
| dot | 矩阵乘法 |
| trace | 计算对角线元素的和 |
| det | 计算矩阵行列式 |
| eig | 计算方阵的本征值和本征向量 |
| inv | 计算方阵的逆 |
| pinv | 计算方阵的 Moore-Penrose 伪逆 |
| qr | 计算 QR 分解 |
| svd | 计算奇异值分解(SVD) |
| solve | 解线性方程组 Ax = b,其中 A 为一个方阵 |
| lstsq | 计算 Ax = b 的最小值 |
Numpy 的文件输入输出
|
|
array([[1., 2., 3., 4.],
[5., 6., 7., 8.],
[2., 3., 4., 5.]])
|
|
[[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]
[20 21 22 23 24]]
[[25 26 27 28 29]
[30 31 32 33 34]
[35 36 37 38 39]
[40 41 42 43 44]
[45 46 47 48 49]]]
|
|
array([[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24]],
[[25, 26, 27, 28, 29],
[30, 31, 32, 33, 34],
[35, 36, 37, 38, 39],
[40, 41, 42, 43, 44],
[45, 46, 47, 48, 49]]])
|
|
|
|
array([[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24]],
[[25, 26, 27, 28, 29],
[30, 31, 32, 33, 34],
[35, 36, 37, 38, 39],
[40, 41, 42, 43, 44],
[45, 46, 47, 48, 49]]])
补充方法
获取最大值或最小值的位置
|
|
array([[ 0, 1, 2, 3, 4, 5],
[ 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17],
[18, 19, 20, 21, 22, 23]])
|
|
array([3, 3, 3, 3, 3, 3])
|
|
array([5, 5, 5, 5])
|
|
array([0, 0, 0, 0, 0, 0])
小数四舍五入
|
|
array([0.98162522, 0.34459695, 0.22603344, 0.14799318, 0.34621457,
0.78629889])
|
|
array([0.98, 0.34, 0.23, 0.15, 0.35, 0.79])
排序
|
|
array([ 0.76489147, 0.65253326, -1.18840851, 1.072042 , 0.84549233,
-0.45669231])
|
|
array([-1.18840851, -0.45669231, 0.65253326, 0.76489147, 0.84549233,
1.072042 ])
|
|
[[ -7.17969463 -1.44401898 -3.04804793]
[ -8.68580105 1.55168534 -10.53525551]
[ -7.26578011 -12.26002953 -8.4707146 ]
[ 10.16939017 -14.70839867 5.48670214]
[ -8.65931279 -12.05255559 -5.20118478]]
[[ -7.17969463 -3.04804793 -1.44401898]
[-10.53525551 -8.68580105 1.55168534]
[-12.26002953 -8.4707146 -7.26578011]
[-14.70839867 5.48670214 10.16939017]
[-12.05255559 -8.65931279 -5.20118478]]
|
唯一化
|
|
array(['Bob', 'Joe', 'Will'], dtype='<U4')
|
|
array(['Bob', 'Joe', 'Will', 'ding'], dtype='<U4')
